{kind=link}
Robots.txt — это текстовый файл, который располагается в корне сайта —
http://site.ru/robots.txt
Главное его предназначение — это задавать определённые директивы поисковым системам — что и когда делать на сайте.

Содержание:
Самый простой Robots.txt
Самый простой robots.txt, который всем поисковым системам, разрешает всё индексировать, выглядит вот так:
Disallow:
Если у директивы Disallow не стоит наклонный слеш в конце, то разрешены все страницы для индексации.
Такая директива полностью запрещает сайт к индексации:
Disallow: /
User-agent — обозначает для кого предназначены директивы, звёздочка обозначает что для всех ПС, для Яндекса указывают User-agent: Yandex.
В справке Яндекса написано, что его поисковые роботы обрабатывают User-agent: *, но если присутствует User-agent: Yandex, User-agent: * игнорируется.
Директивы Disallow и Allow
Существуют две основные директивы:
Disallow – запретить
Allow – разрешить
Пример: На блоге мы запретили индексировать папку /wp-content/ где находятся файлы плагинов, шаблон и.т.п. Но так же там находятся изображения, которые должны быть проиндексированы ПС, для участия в поиске по картинкам. Для этого надо использовать такую схему:
Allow: /wp-content/uploads/ # Разрешаем индексацию картинок в папке uploads
Disallow: /wp-content/
Порядок использования директив имеет значение для Яндекса, если они распространяются на одни страницы или папки. Если вы укажите вот так:
Disallow: /wp-content/
Allow: /wp-content/uploads/
Изображения не будут загружаться роботом Яндекса с каталога /uploads/, потому что исполняется первая директива, которая запрещает весь доступ к папке wp-content.
Google относится проще и выполняет все директивы файла robots.txt, вне зависимости от их расположения.
Так же, не стоит забывать, что директивы со слешем и без, выполняют разную роль:
Disallow: /about Запретит доступ ко всему каталогу site.ru/about/, так же не будут индексироваться страницы которые содержат about — site.ru/about.html, site.ru/aboutlive.html и.т.п.
Disallow: /about/ Запретит индексацию роботам страниц в каталоге site.ru/about/, а страницы по типу site.ru/about.html и.т.п. будут доступны к индексации.
Регулярные выражения в robots.txt
Поддерживается два символа, это:
* — подразумевает любой порядок символов.
Пример:
Disallow: /about* запретит доступ ко всем страницам, которые содержат about, в принципе и без звёздочки такая директива будет так же работать. Но в некоторых случаях это выражение не заменимо. Например, в одной категории имеются страницы с .html на конце и без, чтобы закрыть от индексации все страницы которые содержат html, прописываем вот такую директиву:
Теперь страницы site.ru/about/live.html закрыта от индексации, а страница site.ru/about/live открыта.
Ещё пример по аналогии:
Allow: /about/*.html #разрешаем индексировать
Disallow: /about/
Все страницы будут закрыты, кроме страниц которые заканчиваются на .html
$ — обрезает оставшуюся часть и обозначает конец строки.
Пример:
Disallow: /about — Эта директива robots.txt запрещает индексировать все страницы, которые начинаются с about, так же идёт запрет на страницы в каталоге /about/.
Добавив в конце символ доллара — Disallow: /about$ мы сообщим роботам, что нельзя индексировать только страницу /about, а каталог /about/, страницы /aboutlive и.т.п. можно индексировать.
Директива Sitemap
В этой директиве указывается путь к Карте сайта, в таком виде:
Директива Host
Она предназначена только для Яндекса, потому что он с помощью неё определяет главные зеркала сайта и склеивает их по ней. Про склейку сайтов, в обеих поисковых системах, читайте в моём посте — Как я склеивал сайт в Яндексе и Google.
Указывается в таком виде:
Без http://, наклонных слешей и тому подобных вещей. Если у вас главное зеркало сайта с www, то пишите:
www.site.ru
Пример robots.txt для Битрикс
Disallow: /*index.php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?*
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*action=*
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*PAGEN_*
Disallow: /*PAGE_*
Disallow: /*SHOWALL
Disallow: /*show_all=
Host: sitename.ru
Sitemap:
https://www.sitename.ru/sitemap.xml
Пример robots.txt для WordPress
После того, когда были добавлены все нужные директивы, которые описаны выше. Вы должны получить примерно вот такой файл robots:
Это так сказать базовый вариант robots.txt для wordpress. Здесь присутствует два User-agent-a – один для всех и второй для Яндекса, где указывается директива Host.
Мета-теги robots
Существует возможность закрыть от индексации страницу или сайт не только файлом robots.txt, это можно сделать при помощи мета-тега.
<meta name=«robots» content=«noindex, nofollow»>
Прописывать его надо в теге и этот мета тег запретит индексировать сайт. В WordPress существуют плагины, которые позволяют выставлять такие мета теги, например – Platinum Seo Pack. С помощью него можно закрыть от индексации любую страницу, он использует мета-теги.
Директива Crawl-delay
С помощью этой директивы можно задать время, на которое должен прерываться поисковый бот, между скачиванием страниц сайта.
Crawl-delay: 5
Таймаут между загрузкой двух страниц будет равен 5 секундам. Чтобы уменьшить нагрузку на сервер, обычно выставляют 15-20 секунд. Это директива нужны для больших, часто обновляемых сайтов, на которых поисковые боты просто «живут».
Для обычных сайтов/блогов эта директива не нужна, но можно таким образом ограничить поведение других не актуальных поисковых роботов (Rambler, Yahoo, Bing) и.т.п. Ведь они тоже заходят на сайт и индексируют его, создавая тем самым нагрузку на сервер.
Проверить robots.txt
Чтобы проверить robots.txt для Google, надо зайти в панель вебмастер:
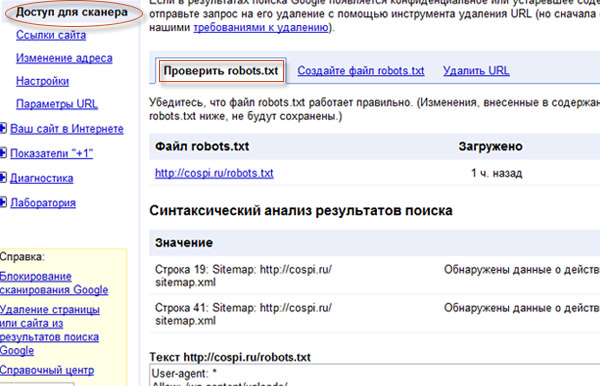
Тут вы сможете проверять все директивы на работоспособность и экспериментировать с ними.
Проверить robots.txt для Яндекса можно тоже в его Панели Вебмастер, перейдя вот по этой
ссылки.
Так же существуют сервисы генераторы robots.txt, которые помогут вас сделать базовые настройки, вот некоторые из них:
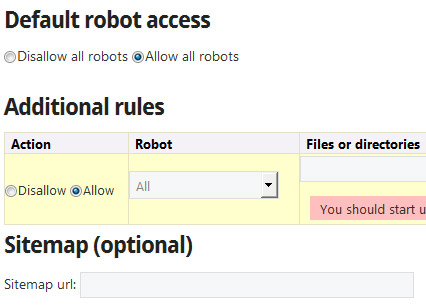
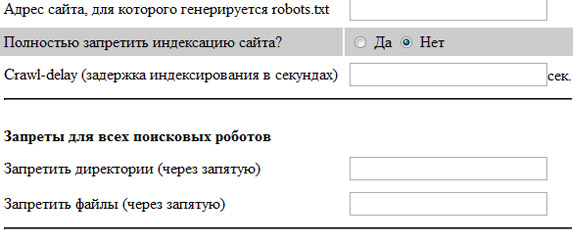
На этом всё, спасибо за внимание и не забываем подписываться на обновление блога