Добрый день всем читателям cospi.ru! Хочу сегодня обратить ваше внимание на поисковик Google и как он индексирует сайты, а точнее на те дубли контента, которые постоянно попадают в индекс, и не имеет значение — закрыты при этом они в robots.txt или нет.
Речь идёт о страницах с replytocom:
Такие страницы образуются из-за оставленных комментариев к записям и чем больше комментариев, тем больше подобных страниц попадают в индекс.
Важный нюанс – такая генерация страниц с replytocom, появляется тогда, когда на сайте используется древовидная система комментирования с возможностью отвечать на комментарии пользователей.
Как определить дубль контента на сайте?
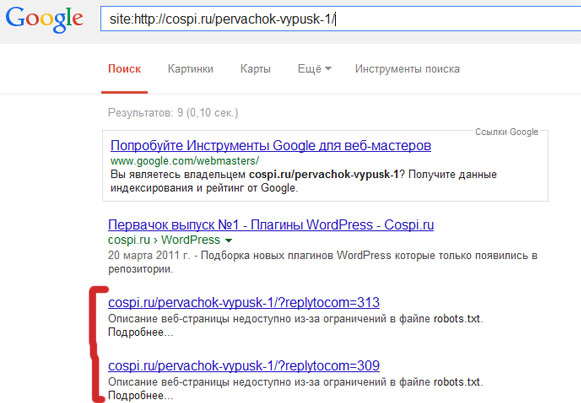
На самом деле всё очень просто, берёте адрес страницы, на которых оставлено несколько комментариев и проверяете её в Google, с помощью специального поискового оператора:
Чаще всего, Google показывает основную страницу и ниже надпись — «Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше». В любом случае, если у вас установлены древовидные комментарии, то дубли страниц с replytocom обязательно будут.
Вот так выглядит url c «replytocom»:
Устраняем проблему
Как уже известно, директива в роботсе Disallow: /*?* не спасает, хоть и пишет Google, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt», но тем не менее в индекс её включает.
Значит надо просто удалить возможность генерации таких ссылок, и сделаем это с помощью правки файла coment-template.php, который находиться в корне директории wp-includes.
В этом файле ищем функцию function get_comment_reply_link и удаляем код, который выделен красным на скриншоте (кликабельно):

Мы удалили участок кода, которые создаёт саму ссылку с replytocom и тем самым генерирует дублирующие страницы.
Сейчас ссылка на ответ к комментарию будет иметь вид:
Вместо старого:
У новых записей на блоге теперь не будет дублирующих страниц в индексе, но вот что делать со старыми дублями, которые уже «сидят» в индексе? Ведь мы убрали только ссылки, по которым поисковые боты могут попасть на страницу, а сами дубли, физически остались на сайте и Google будет по-прежнему индексировать их.
А выход один: запретить доступ поисковому боту к подобным страницам в панели вебмастера (Сканирование » Параметры URL):
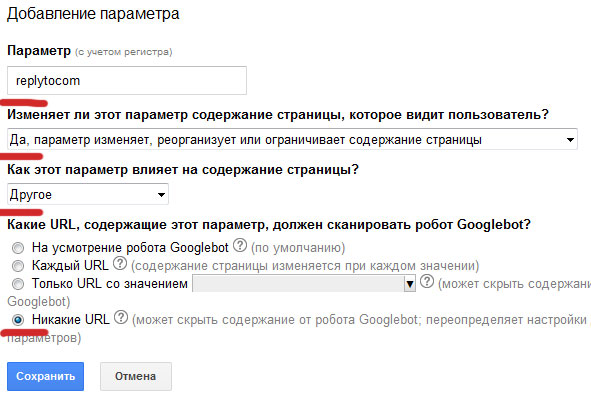
Вот и всё, после этих манипуляций у вас не должны появляться дубли с replytocom. И теперь, количество всех проиндексированных страниц сайта в Google, может наконец-то сравняется с количеством страниц в Яндексе :).