Собрав полное семантическое ядро, вы всегда получите конкурентное преимущество за счёт большего охвата аудитории и, следовательно, больше заказов, покупок, лидов.
В этой публикации я постарался изложить весь процесс начального сбора ключевых фраз — сервисы, программы, принципы поиска и работы с полученными данными. А так же, описан способ составления базового списка минус слов (на основе собранного семантического ядра), который исключит 95% всех не целевых показов!
Способ сбора универсальный и подойдёт не только для рекламной кампании в Яндекс Директ, но и для формирования полноценной семантики для поискового продвижения (SEO). Одно лишь отличие — собирая семантическое ядро для контекстной рекламы, обычно не уходят так глубоко в НЧ фразы. А методы фильтрации и составления списка минус слов — одинаковый.
1-ый шаг. Сбор маркерных слов для парсинга в Яндекс WordStat
Статью пишу на основе одной из последних моих работ — лыжное снаряжение, техника катания и т.д.
Для поиска маркерных слов используем:
- Сам сайт, его разделы с товарами или услугами;
- Сайты конкурентов. Анализируем внешне по разделам и услугам, так и с помощью сервисов — megaindex, key.so и тому подобных;
- Сервисы синонимов;
- Правая и левая колонка в Яндекс WordStat, блок «с этой фразой ищут» под поисковой выдачей.
Маркерные слова/словосочетания — это только направления для дальнейшего изучения, «копания» вглубь, так сказать. Если в список уже добавили фразу — «выбор лыж», то не надо добавлять вложенную «выбор горных лыж». Все вложенные фразы будут найдены после парсинга в Key Collector.
Главная задача — собрать максимум маркерных слов (направлений), проверить синонимы, сленговые слова и сформировать общий список, по которому будем «копать» дальше.
Формировать удобно в визуальном виде, к примеру в MindMap и выглядит вот так:

Огромная польза от такой визуализации, лично для меня, что если раскрыть все направления, сразу понимаешь, что многозадачность надо выключать и работать только с одним разделом, а не сразу со всеми. А то с последовательностью действий иногда возникают проблемы.
В моём случае всё просто, так как категория интересов одна — лыжи. Поэтому не потребовалась подобная масштабная проработка:

Таблица с вопросами удобна для больших проектов. Не знаю, как её назвать профессионально, но через такие вопросы, можно существенно расширить семантическое ядро, найти новые интенты, о существовании которых даже не подозревал в начале.
Собранные фразы перемножаются, а затем проверяются на частотность в Wordstat. Частотные фразы добавляются для дальнейшего изучения.
Интент — это то, ради чего пользователь вводит запрос в поисковую систему. Можно сказать его «боль». Набор из ключевых фраз может объединяться по одному интенту, то есть быть вызванным одним мотивом, хотя при этом написание и набор слов могут различаться.
Надо ли платные сервисы и программы для сбора семантического ядра?
Я использую программу Кей коллектор и все ниже описанные действия провожу в нём. Если её нет, то собрать полное ядро вряд ли получится. Вы сможете, конечно, вручную «походить» по Wordstat, расширение Wordstat Assistant в этом сильно поможет, взять ещё фразы из бесплатных баз, вроде Букварикса. Но это всё будет малая часть того, что действительно можно собрать.
В некоторых ситуациях этого достаточно, хотя я сторонник создания максимально полной семантики, особенно если тематика сайта небольшая и тематического трафика мало. В таких случаях целесообразно собрать всё, чтобы максимально охватить свою нишу.
Если у вас один сайт, то выгоднее будет заказать услугу сбора семантического ядра на аутсорсе. Заплатите 3-5 тысяч рублей, но получите полное ядро с максимум ключевых фраз, без необходимости покупать софт, оплачивать сервисы и так далее.
Для Яндекс Директ ключевые фразы в Key Collector собираю редко, только когда большие рекламные кампании, много направлений… Для маленьких и средних ниш достаточно Wordstat и проработка синонимов.
Опять же, если предполагается создание рекламных кампаний для одного вида деятельности, и вы сами в нём хорошо разбираетесь, то совсем не обязательно тратить деньги на сервисы и просматривать фразы и объявления конкурентов.
Чаще всего директологи плохо разбираются в объекте рекламы, и если вы рекламируете ваш товар/услугу, то вы априори подберете правильные ключевые фразы и лучшие объявления, которые затронут необходимые струны вашей целевой аудитории. Вам только надо разобраться в некоторых тонкостях и последовательностях работы. Что я и постараюсь подробно описать в этом цикле статей.
2-ой шаг. Сбор ключевых фраз в Яндекс WordStat
Собранные маркерные слова пропускаем через левую колонку Wordstat ![]() в Key Collector.
в Key Collector.
Для экономии времени большие направления можно разбивать вот так ёлочкой:

Вордстат даёт возможность просмотреть только 2000 вложенных фраз. Это 40 страниц. Если пролистаете к 40-ой странице по фразе «лыжи», то увидите, что список заканчивается на выражении с частотностью 62 показа. Для полного семантического ядра этого будет мало, так как дальше ещё может быть несколько сотен низкочастотных фраз, которые могут приносить дополнительный трафик.
Метод «елочкой» позволит сократить время и не проводить повторную итерацию парсинга полученных ключевых фраз после первого сбора. Key Collector возьмёт все фразы с Wordstat по данному маркерному слову, вплоть до частотности в 1, не ограничиваясь стандартными двумя тысячами.
Сбор ключевых фраз конкурентов и базы
Используем сервис megaindex, key.so или serpstat.com. Желательно проработать 5-10 прямых конкурентов. Из бесплатных баз, могу посоветовать
Букварикс.
Наблюдение: если первоначально хорошо проработаны маркерные слова, синонимы, сленговые выражения, то Wordstat даёт 70-80% поисковых запросов, а оставшиеся добираются от конкурентов и букварикса.
Эти фразы не стоит мешать со всеми, а добавлять лучше в отдельную группу в кей коллекторе.
Обратите внимание, чтобы при добавлении стояла галочка «Не добавлять фразу, если она есть в любой другой группе»:
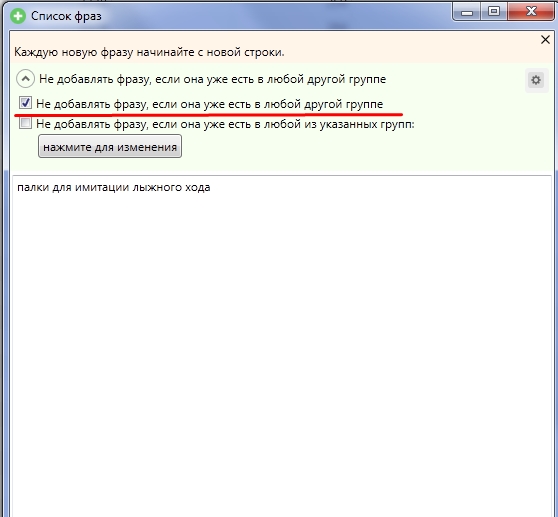
Этим ограничением недопустим добавление дублирующих фраз в общее семантическое ядро.
Букварикс — отдельная история. Очень много неявных дублей, запросы различаются только перестановкой слов. Находит много фраз, но 70-80% из них не подойдут нам. Добавляю в отдельную группу, но не вычищаю и не работаю с ней, а только ищу интересующие меня фразы поиском, чтобы посмотреть, можно ли чем дополнить основную семантику с него или нет.
Сбор поисковых подсказок
Как только собрали все фразы в WordStat и конкурентов, следует объединить их в мульти-группы ![]() , отсортировать по базовой частотности (обычно от 100, либо от 50 если ниша небольшая) и выбрать целевые фразы для сбора поисковых подсказок по ним:
, отсортировать по базовой частотности (обычно от 100, либо от 50 если ниша небольшая) и выбрать целевые фразы для сбора поисковых подсказок по ним:
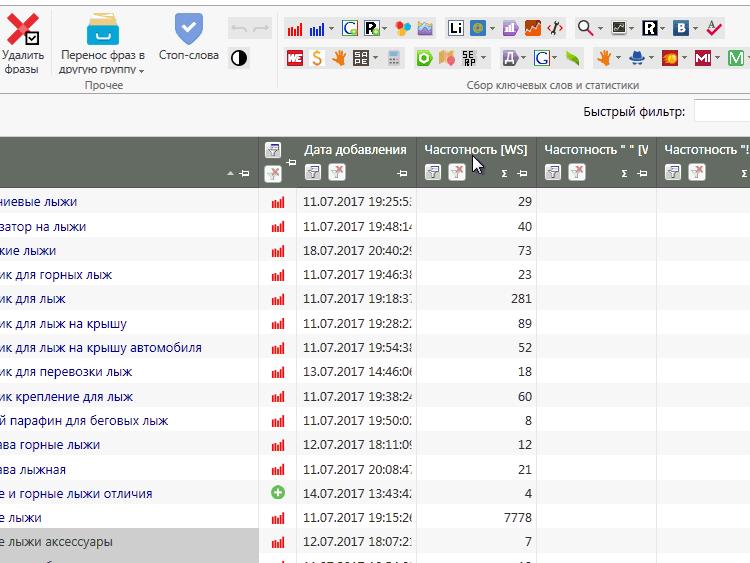
Вторая итерация сбора фраз для семантического ядра
На данном этапе собрано почти всё :). Для полноценного ядра требуется заглянуть ещё глубже и посмотреть вложенные фразы для найденных фраз в ходе вышеописанных действий.
Для фраз, собранных методом «ёлочки» не надо проводить повторную итерацию сбора, а вот для запросов найденных у конкурентов, выбранных в буквариксе и поисковых подсказок — стоит.
Для повторной итерации я сортирую собранные фразы по базовой частотности и выбираю целевые (так как мы ещё не чистили стоп словами, не стоит выделять всё подряд) до значения частотности в 100 единиц. Заново запускаю по ним пакетный сбор из левой колонки Yandex WordStat ![]() .
.
Важно: не мешайте все повторные сборы вместе, создавайте отдельные группы для конкурентов, букварикса, основному ядра собранному по маркерным словам, парсинг по второй итерации и так далее. Чем подробнее вы раздробите в моменте сбора семантики, тем проще её будет чистить от нецелевых фраз. Объединить всегда успеете!
Повторюсь для начинающих
Такой глубокий сбор необходим в первую очередь для поискового продвижения и для создания рекламных кампаний в Google Adwords, так как там цена клика вложенных ключевых фраз не отличается от родительской, в отличие от Яндекс Директ. Подробнее с ценообразованием в системах контекстной рекламы разберёмся в следующих публикациях.
Суть: для Директа не обязательно собирать ВСЕ фразы в тематике, для Adwords и SEO — желательно.
3-ий шаг. Удаляем нецелевые фразы
На данном этапе надо удалить явно не целевые запросы. Проделать это можно с помощью универсальных стоп-слов. Я собираю их в
этом файле на Google Docs. Если у вас есть собственная база универсальных стоп слов, пришлите мне на почту [email protected], я их размещу в этой таблице, всем читателям на пользу.
Делим все слова на: целевые / нецелевые / сомневаюсь
Этот шаг нужен для создания общего списка минус фраз, который можно использовать сразу на всю рекламную кампанию и для чистки всей семантики от нецелевых поисковых запросов.
На выходе получаем список из целевых и стоп слов с помощью которых мы будем чистить и проверять семантическое ядро.
Я сторонник параноидального способа, который занимает много времени, но способен исключить 95% всех не целевых ключевых фраз.
По опыту скажу, чем качественнее проработан список минус слов и фраз, тем меньше в Яндекс Директ проскакивают не целевые показы и показы по синонимам, которые так любит добавлять поисковик для кампаний новичков, которые не уделяют должного внимания этой процессу.
У вас будет чистейший трафик, так как мы все уникальные слова в семантике проверили в ручном режиме и определили их принадлежность.
Алгоритм действий:
1. Выгружаем весь список ключевых фраз в notepad.
2. Превращаем фразы в список слов. Их будет много, если брать мой пример с семантикой под лыжи, то около 60 тысяч.
Пример автоматической замены пробела на «перенос строки» в notepad:
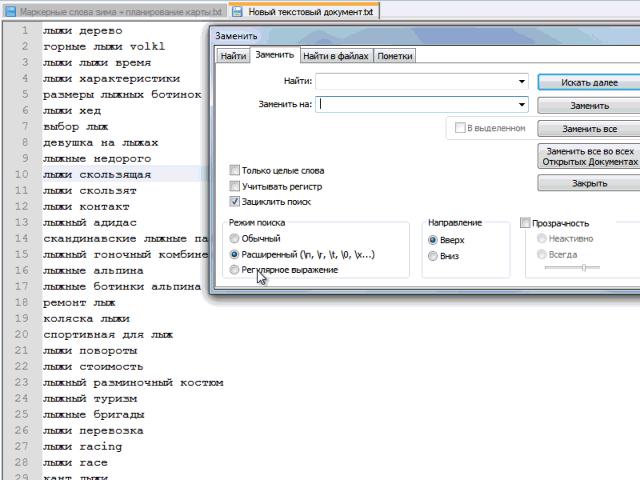
Этот шаг некоторые делают в Word, еще какими-то программными средствами. Я для себя выбрал блокнот notepad. Главный плюс — минимум действий для получения желаемого результата.
3. Копируем все слова в Excel и удаляем дубли:

Получен список всех уникальных слов в нашей семантике. Далее каждое слово я прохожу с вопросом: целевое / не целевое / сомневаюсь. У слов, которые явно целевые, ставлю 1 в соседней ячейке, у сомневающегося 2, у минус слов ничего не ставлю, так как их будет больше всего.
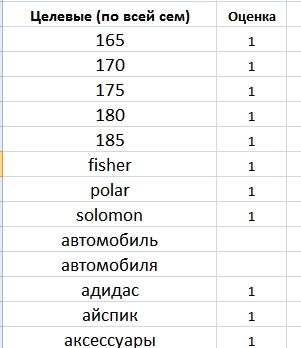
Все сомневающиеся слова проверяю на конкретных поисковых фразах в семантическом ядре (быстрый поиск кей коллектора).
На выходе получаем список целевых слов и минус-слов. После чего, можно отдохнуть и попробовать осмыслить весь процесс и понять описываемую последовательность.
Резюмирую статью
Использую слово итерация, чтобы были понятны проделываемые действия. А то слово «сбор» общее и легко запутаться, особенно новичку.
- Собираем все маркерные фразы (наш сайт, конкурентные, правая/левая колонка WordStat, синонимы);
- Парсинг фраз по маркерным словам в левой колонке WordStat (#первая итерация);
- Добавление в отдельные группы фразы конкурентов и с букварикса;
- Если на втором шаге сбор был без «ёлочки», то объединяем в мульти-группу (
 ) группы конкурентов и группу собранную на основе маркерных слов, сортируем по частотности (от 100, либо 50 если тематика небольшая) и выбираем целевые фразы для повторного сбора (#вторая итерация).
) группы конкурентов и группу собранную на основе маркерных слов, сортируем по частотности (от 100, либо 50 если тематика небольшая) и выбираем целевые фразы для повторного сбора (#вторая итерация). - Объединяем в мульти-группы три группы: первая итерация, конкуренты, вторая итерация. Сортируем по базовой частотности (от 100, либо 50). Выбираем опять целевые и запускаем сбор поисковых подсказок.
- Чистим всё полученное общими стоп-словами. Начинаем формировать основой список минус слов и целевых слов.
Сейчас вот задумался. Наверно зря я объединил описание процесса сбора семантики для SEO и Директа. По большому счёту, второй шаг c углублённым сбором абсолютно всех фраз, для контекста не нужен. Нам нужные только ВЧ и СЧ фразы (частотность от 100 и выше, но зависит от тематики) и самые целевые НЧ.
В любом случае, пункты под номером 1 и 3 абсолютно одинаковы для обоих видов работ.
В следующих публикациях мы начнём группировать и сегментировать ключевые фразы, а так же вычищать семантику от не целевых фраз, неявных дублей и всего того мусора, которого примерно 70-80% от собранного на данном этапе.
Подписывайтесь на обновления блога в
Твиттере, либо по Email (форма в сайдбаре). Один раз в две недели я провожу рассылку о новых публикациях. До скорого!